这个博客系统梳理了大模型领域的核心概念、技术原理与发展脉络,适合快速建立完整知识框架。
一、底层引擎:大语言模型 (LLM)
核心定义与架构
-
LLM 全称:Large Language Model(大语言模型),简称大模型
-
底层架构:基于 Transformer(2017 年 Google 团队在论文《Attention is All You Need》中提出)
这个图看不懂没关系,你只需要知道大模型的底层引擎就是它就好
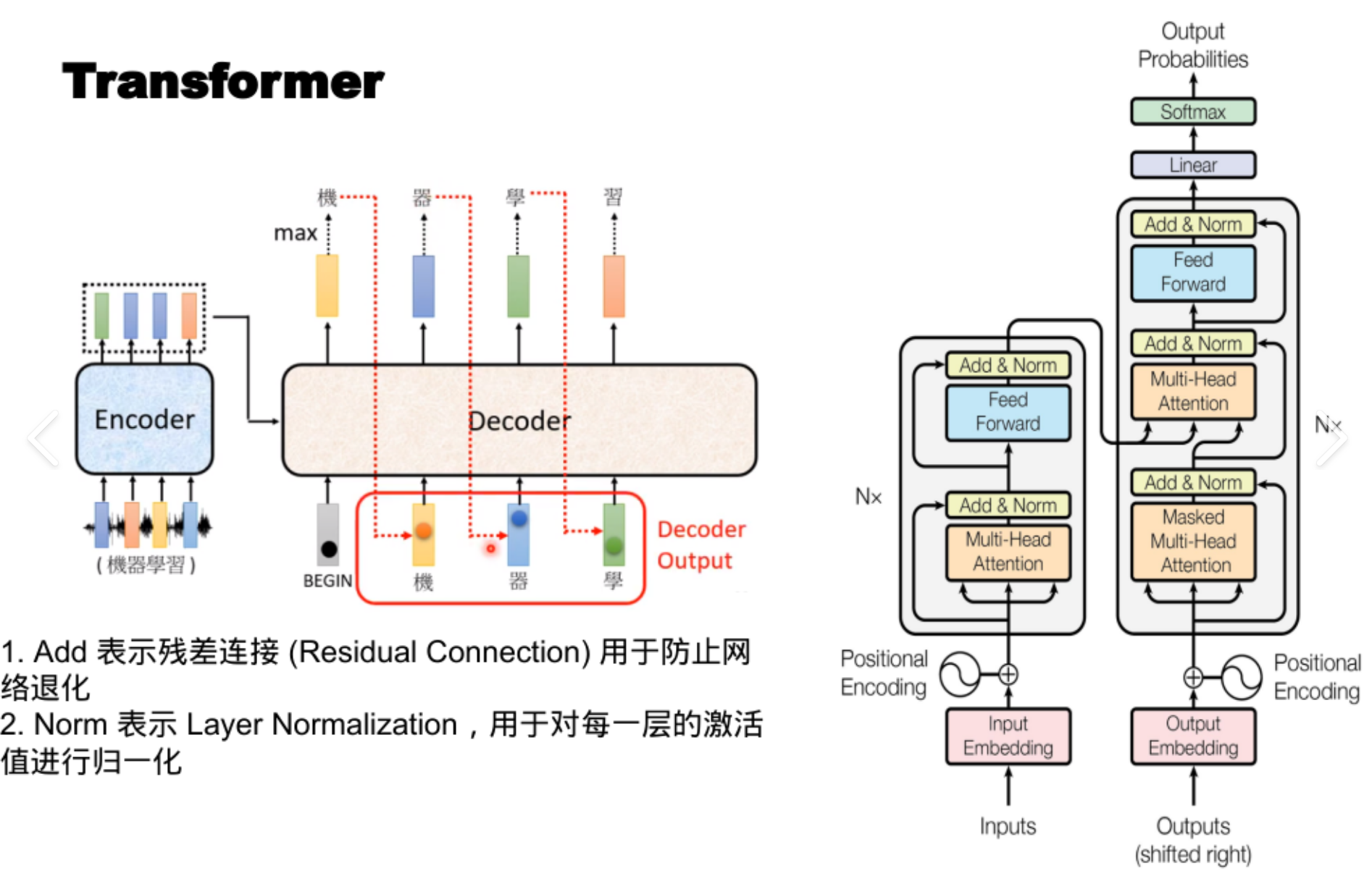
-
工作原理:本质是文字接龙游戏,通过预测下一个概率最高的词,模型吐出这个词之后,它会把你刚才的词抓回来,追加到你的输入的后面,它拿着这个新的输入,再去预测下一个词,一直循环,知道大模型发现自己要说的话全部说完了,这个时候就会输出一个特殊的结束标识符,整个回答到这里就结束了,这也是为啥大模型的回答是一个字一个字的蹦出来的原因。
发展里程碑
| 时间 | 事件 | 意义 |
|---|---|---|
| 2017 年 | Transformer 架构提出 | 奠定大模型技术基础 |
| 2022 年底 | GPT-3.5 发布 | 首个达到可用级别的大模型,让 AI 对话真正普及 |
| 2023 年 3 月 | GPT-4 发布 | 大幅提升 AI 能力天花板,支持多模态输入 |
| 2023 年后 | Claude、Gemini 等模型涌现 | AI 赛道从 OpenAI 独角戏变为多强竞争,推动技术快速迭代 |
二、数据处理单元:Token
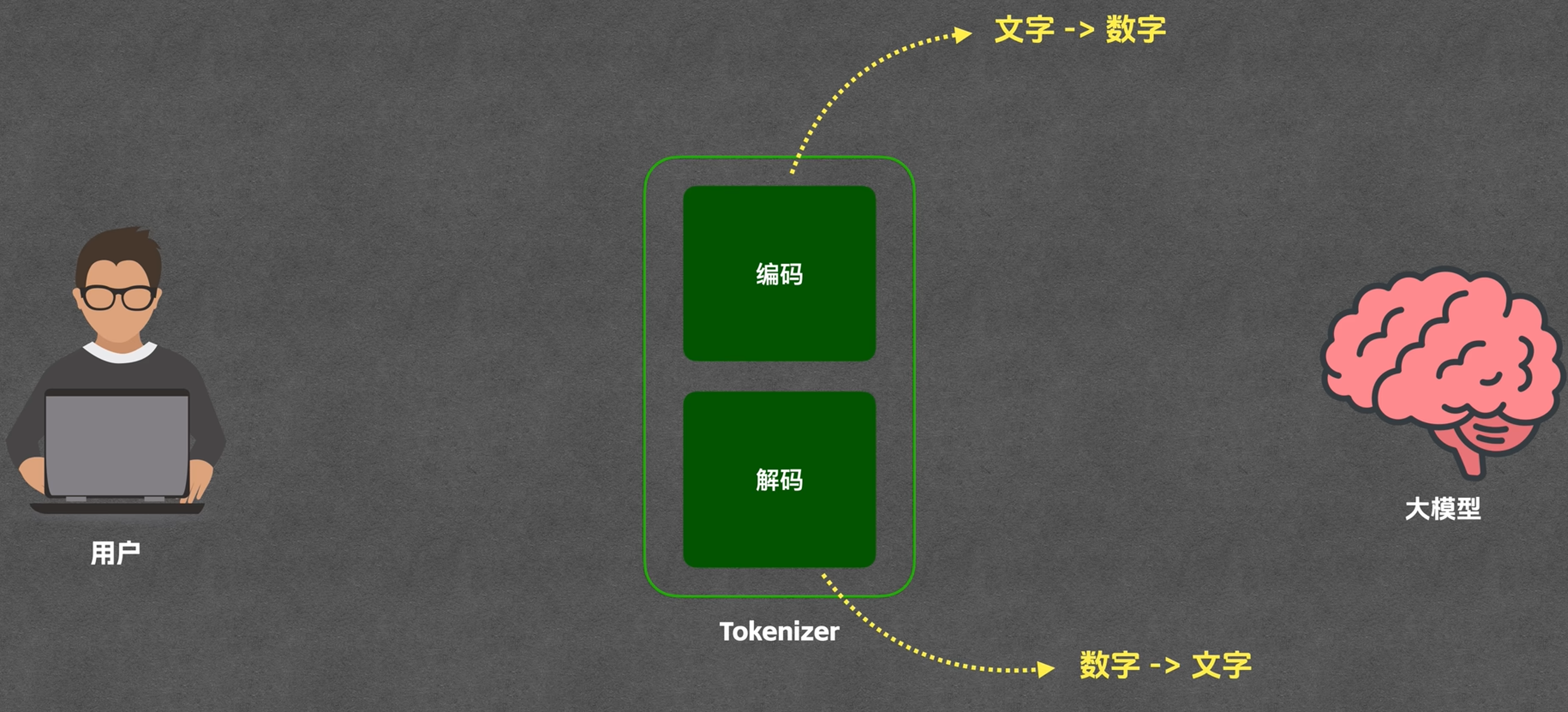
核心特性
- 定义:大模型处理文本的最基本单位,通过 Tokenizer(分词器)将文本切分为片段
- 编码过程:分两步 ——①文本切分为 Token(文字)②映射为 Token ID(数字),发给大模型。
- 解码过程:模型一顿运算,最终吐出来一个 Token ID发给Tokenizer 将 Token ID 还原为token(无需切分步骤,因为一次只给一个token)
Token 与自然语言单位的关系
| 语言单位 | 与 Token 的关系 | 示例 |
|---|---|---|
| 中文词语 | 非一一对应,可能被拆分 | “工作坊”→“工作”+“坊” |
| 英文单词 | 常见词通常对应 1 个 Token | “hello”→1 个 Token |
| 复杂单词 | 可能被拆分 | “helpful”→“help”+“ful” |
| 特殊字符 | 可能需多个 Token 表示 | “✅”→3 个 Token |
量化参考
- 1 个 Token ≈ 0.75 个英文单词
- 1 个 Token ≈ 1.5-2 个汉字
- 40 万 Token ≈ 60-80 万汉字 或 30 万英文单词
补充说明:Token 的切分基于BPE(字节对编码)算法,是模型自主学习的文本切分规则,能平衡语言效率和模型处理能力。
三、大模型的临时记忆体:Context
核心概念
出现的原因:大模型之前是你给它输入,它给你输出,那它是如何记住聊天的内容的呢?背后的程序会把你之前的整段的对话历史找过来一起发过去,这样就是引出了模型有了对话历史,模型每次看到的都是完整的对话内容,这就引出了Context。
- 定义:大模型每次处理任务时接收的信息总和,相当于模型的 “临时记忆”
- 组成部分:用户问题、对话历史、当前输出 Token、工具列表、System Prompt 等
- 容量限制:由 Context Window(上下文窗口)定义,即最大可处理的 Token 数量
主流模型 上下文窗口(Context Window) 对比
注意:一个token约等于1.5个汉字
| 模型 | Context Window(Token) | 约合汉字数量 |
|---|---|---|
| GPT-4.5 | 105 万 | 约 157.5 万 |
| Gemini 3.1 Pro | 100 万 | 约 150 万 |
| Claude Opus 4.6 | 100 万 | 约 150 万 |
突破 Context Window 限制的方案
- RAG 技术(检索增强生成):从知识库中抽取与问题最为匹配的几个片段,仅将这几个片段发送给大模型,降低 Token 消耗,同时解决大模型 “知识滞后” 的问题。
四、指令交互:Prompt
Prompt Engineering 提示词工程
- 核心原则:清晰、具体、明确(避免模糊、歧义的指令)
- 现状:曾经是提升模型效果的关键手段,但现在重要性下降,原因:
- 门槛低(本质是 “把话说清楚”)
- 大模型能力提升,可自动推测用户模糊意图
Prompt定义与分类
Prompt定义:
- Prompt:给大模型的问题或指令,直接决定模型输出质量
Prompt 分类:
有了他们的配合大模型既能守住规矩,又能完成你的具体的请求。
- User Prompt:用户输入的具体任务(如 “帮我写一首诗”)
- System Prompt:开发者后台配置的人设与做事规则(如 “你是一个耐心的数学老师,当学生问你数学问题时,不要直接给答案,而是要一步步引导学生思考,帮助他们理解解题的思路”)
五、感知外部环境:Tool
核心作用
- 定义:大模型调用的外部函数,使其能够感知和影响外部环境
- 解决痛点:弥补大模型无法获取实时信息(如天气、新闻)、计算能力有限(如复杂数学运算)、无法访问外部系统(如数据库、API)等弱点
工作流程

- 用户提问 → 平台转发(含工具列表)
- 大模型分析 → 生成工具调用指令
- 平台执行调用(真正的工具,也就是函数) → 获取结果
- 大模型整理结果 → 自然语言输出
角色分工

| 角色 | 职责 |
|---|---|
| 大模型 | 选择工具、生成参数、归纳结果 |
| 工具 | 执行具体功能(如查询天气、调用计算器、访问数据库) |
| 平台 | 转发信息、执行工具调用、处理权限与安全校验 |
六、工具标准化:MCP(负责把工具接进来)
-
全称:Model Context Protocol(模型上下文协议)
-
本质:统一的工具接入标准,解决不同平台工具接入规范不统一的问题
类比:就像手机都统一用 Type-C 充电口,开发者只需要做一次适配,就能在所有支持 Type-C 的设备上使用
-
价值:工具开发者只需按 MCP 规范开发一次,即可在所有支持 MCP 的平台使用,大幅降低跨平台适配成本
补充:Function Calling(模型与外部工具交互的一种能力)
定义:Function Calling(函数调用)是大模型连接现实世界的核心接口,它让原本只能 “生成文字” 的模型,拥有了调用外部工具、执行真实操作的能力。
**底层逻辑:**先看最底层:Function Calling。模型本身没有任何执行能力,它能做的是:接收你传入的 tools 列表,看到每个工具的名字、description 和参数结构,然后在合适的时候返回一个结构化的调用请求
和 Agent、MCP 的关系
- Function Calling 是底层能力:只负责生成工具调用指令,不关心流程控制
- Agent 是上层应用:基于 Function Calling,加上规划、记忆、循环执行等逻辑,实现 “自主完成任务”
- MCP 是标准化协议:让不同平台的工具都能按统一格式被 Function Calling 调用,解决 “适配成本高” 的问题
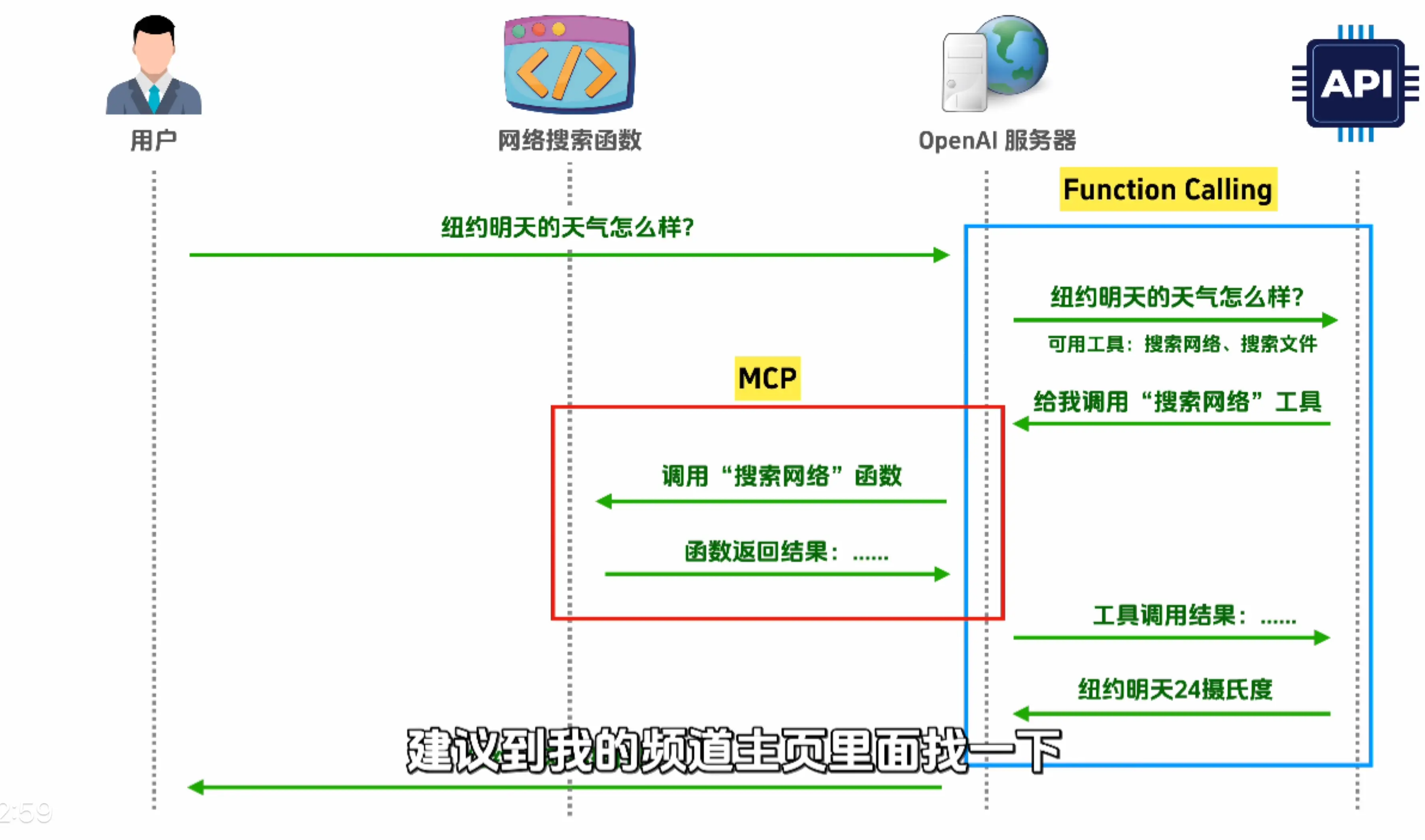
这个图片的解释:
Function Calling:图里蓝色框标注的部分,是大模型生成工具调用指令的核心能力
MCP:图里红色框标注的部分,是工具与大模型之间的标准化通信协议,解决不同工具接入不统一的问题
Agent:把这些部分串起来的整体,也就是 “能自主调用工具完成任务的系统”
七、自主决策系统:Agent

- Agent 定义:能够自主规划、自主调用工具,持续工作直至完成用户任务的系统
- 核心能力:多步骤推理、工具选择、流程控制、错误修正
- 代表产品:Claude Code、OpenAI Codex、Gemini CLI 等
- 典型构建模式:ReAct(推理 + 行动)、Plan and Execute(规划 + 执行)等
补充说明:Agent 是大模型从 “被动响应” 到 “主动执行” 的关键形态,也是当前 AI 应用落地的核心方向之一。
八、任务定制:Agent Skill(负责如何使用这些工具)
核心功能
- 定义:给 Agent 的说明文档,包含任务规则、执行步骤、输出格式等,相当于给 Agent 的 “操作手册”
- 结构:
- 元数据层:名称(name)、描述(description)(用于 Agent 识别场景)
- 指令层:目标、执行步骤、判断规则、输出格式、示例(用于 Agent 执行任务)
- 例子:
# SKILL.md - 天气查询助手
## 📋 元数据层
### 名称
天气查询助手
### 描述
当用户询问天气相关问题(如城市/地区的实时天气、未来预报、温度、湿度、降水概率、穿衣建议等)时,调用此技能获取准确信息并整理成自然语言回复。
### 触发关键词
天气、气温、温度、下雨、晴天、多云、湿度、风力、穿衣建议、预报
---
## 🎯 指令层
### 任务目标
1. 理解用户的天气查询意图,提取关键信息(目标城市/地区、时间范围、具体需求)
2. 调用天气查询工具获取对应数据
3. 将工具返回的结构化数据整理成清晰、友好的自然语言回复
4. 根据天气情况,主动提供实用的生活建议(如穿衣、出行、防晒/防雨提示)
### 执行步骤
1. **信息提取**:
- 从用户问题中提取:目标城市(如上海、北京)、时间范围(今天/明天/未来3天)、具体需求(温度/降水/风力/穿衣建议)
- 若用户未指定城市,优先使用对话上下文或询问用户补充信息
- 若用户未指定时间,默认查询「当天实时天气+未来24小时预报」
2. **工具调用**:
- 调用`weather_query`工具,传入参数:
- `city`: 提取到的城市/地区名称
- `date`: 查询日期(格式:YYYY-MM-DD,不传默认当天)
- 等待工具返回结构化天气数据(温度、湿度、风力、天气状况、降水概率等)
3. **结果整理**:
- 按「实时天气 → 关键指标解读 → 实用建议」的结构组织内容
- 温度、湿度、风力数据用加粗突出关键信息
- 降水概率超过30%时,明确提醒带雨具
- 温度低于10℃或高于30℃时,补充穿衣/防暑/保暖建议
4. **回复输出**:
- 语言口语化、友好,避免生硬的参数罗列
- 若用户问题存在歧义(如未指定城市),礼貌追问补充信息
- 若工具调用失败,给出备用回复并说明情况
### 判断规则
- ✅ 触发条件:用户问题包含天气相关关键词,或明确询问某地区的气象情况
- ❌ 不触发条件:用户问题与天气无关(如编程、历史、数学题),直接按原问题处理
- ⚠️ 异常处理:
- 若工具返回错误(如城市不存在、接口超时),回复:“抱歉,暂时无法查询到该地区的天气信息,你可以告诉我具体城市名称,我再帮你试试~”
- 若用户问题模糊(如“明天天气怎么样”),回复:“你想查询哪个城市的天气呢?告诉我城市名,我马上帮你看看~”
### 输出格式示例
```text
🌤️ 上海今天天气播报
实时天气:多云
温度:22℃(体感24℃)
湿度:65% | 风力:东北风3级 | 降水概率:10%
💡 今日小贴士:
气温舒适,适合外出活动,早晚温差不大,穿长袖T恤+薄外套即可,紫外线较弱,不用特意防晒哦~
```技术实现


- 存储形式:Markdown 文档(文件名必须为
SKILL.md) - 存放位置:特定目录(如 Claude Code 找到用户目录的
.claude/skills文件夹) - 加载机制:仅在用户问题与技能名称 / 描述相关时加载完整指令,节省 Token 消耗
补充特性:Agent Skill 支持运行代码、引用资源,采用渐进式披露机制,进一步优化 Token 使用效率。
九、概念体系关联
graph LR
A[LM 核心引擎] --> B[Token 数据单位]
B --> C[Context 记忆空间]
C --> D[Prompt 交互接口]
D --> E[Tool 外部能力]
E --> F[MCP 工具标准]
F --> G[Agent 决策系统]
G --> H[Agent Skill 任务定制]补充细节
把策略层、接入层、执行层搞清楚之后,许多MCP vs Skill的争论会自动消失。
